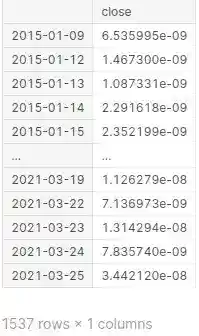
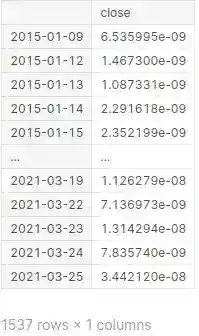
How to implement Realized Volatility python

- Authors

- Name
- Pavel Fedotov
- @pfedprog
Volatility estimators are especially valuable in modelling financial returns and capturing time-variability of financial series.
In this article, we discuss advanced metrics of volatility and measures of integrated quarticity. Besides, we implement the estimators in Pandas, NumPy and SciPy python libraries.
Quarticity and Realized Volatility python
The libraries that we are using in the implementation of the math formulas are
from scipy.special import gamma
import numpy as np
import pandas as pd
The provided code involves statistical or financial calculations using Python's NumPy and Pandas libraries, along with the gamma function from the SciPy library.
Furthermore, we estimate additional volatility estimators that we build upon realized quarticity, realized quad-power quarticity and realized tri-power quarticity.
The realized fourth-power variation or realized quarticity is a consistent estimator of the integrated quarticity
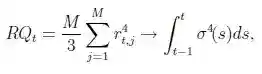
A more robust estimator, particularly in the presence of jumps, is the realized quad-power quarticity
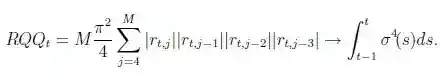
Similarly robust estimator is also the realized tri-power quarticity
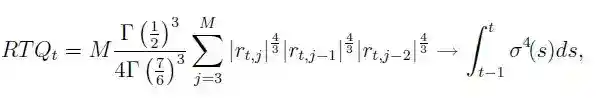
In python an implementation looks as following
def realized_quarticity(series):
series = np.log(series).diff()
return np.sum(series**4)*series.shape[0]/3
df.groupby(df.index.date).agg(realized_quarticity)
The function realized_quarticity calculates the quarticity of a given series. First, it takes the natural logarithm of the input series and then calculates the difference between consecutive elements. After this, it raises each element of the resulting series to the power of 4, sums the results, and then multiplies by the length of the series. Finally, it divides by 3.
The subsequent code applies the realized_quarticity function to a DataFrame df grouped by the date of the index, and aggregates the results of the function for each group.
def realized_quadpower_quarticity(series):
series = np.log(series).diff()
series = abs(series.rolling(window=4).apply(np.product, raw=True))
return (np.sum(series) * series.shape[0] * (np.pi**2))/4
df.groupby(df.index.date).agg(realized_quadpower_quarticity)
This Python code defines a function called realized_quadpower_quarticity, which takes a series of numerical data as input. The function first takes the natural logarithm of the series and calculates the difference between consecutive elements.
Then, it calculates the absolute value of the rolling product of these differences over a window size of 4. The rolling product means that at each point in the series, it considers the current value and the three previous values, and calculates their product.
After obtaining this new series of rolling products, the function sums them all up, multiplies by the length of the series, and then multiplies by π squared, finally dividing by 4.
The larger block of code at the end applies this function to a DataFrame df grouped by the date of the index, and aggregates the results of the function for each group.
def realized_tripower_quarticity(series):
series = np.log(series).diff() ** (4/3)
series = abs(series).rolling(window=3).apply(np.prod, raw=True)
return series.shape[0]*0.25*((gamma(1/2)**3)/(gamma(7/6)**3))*np.sum(series)
df.groupby(df.index.date).agg(realized_quadpower_quarticity)
realized_tripower_quarticity takes a series as input. Here's a breakdown of what the function does:
It first takes the natural logarithm of the input series and then calculates the difference between consecutive elements.
It raises the result to the power of 4/3.
It takes the absolute value of the previous result and calculates a rolling window of size 3. Within this window, it computes the product of the values.
Finally, the function returns a scalar value which is computed using the shape of the series, a constant, and the sum of the rolling window values.
The given snippet applies this function to a DataFrame called df using the groupby operation on the date component of the DataFrame index. It aggregates the results using the function realized_quadpower_quarticity.
Moreover, these estimates assist in estimation of three additional realized volatility estimators:
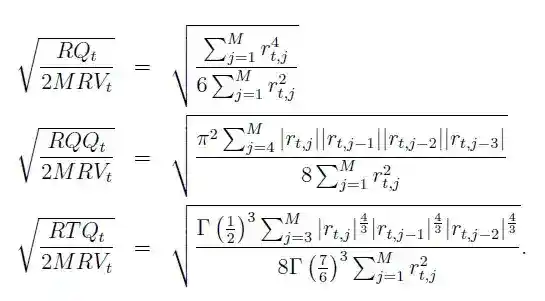
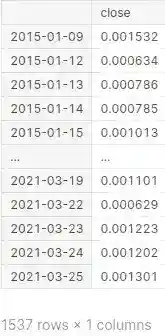
def realized_1(series):
series = np.log(series).diff()
return np.sqrt(np.sum(series**4)/(6*np.sum(series**2)))
df.groupby(df.index.date).agg(realized_1)
realized_1 function takes a series as input and performs the following operations:
It takes the natural logarithm of the input series and then calculates the difference between consecutive elements.
It computes the sum of the fourth power of each element in the resulting series, then divides it by six times the sum of the square of each element in the original series.
It returns the square root of this result.
The function then applies this realized_1 function to a DataFrame called df using the groupby operation on the date component of the DataFrame index.
def realized_2(series):
series = np.log(series).diff()
return np.sqrt(((np.pi**2)*np.sum(abs(series.rolling(window=4).apply(np.product, raw=True))))/(8*np.sum(series**2)))
df.groupby(df.index.date).agg(realized_2)
realized_2 function takes a series as input and performs the following steps:
It computes the natural logarithm of the input series and then calculates the difference between consecutive elements.
It computes the absolute value of the resulting series and applies a rolling window of size 4 to calculate the product of the values within the window.
It then computes the sum of these absolute rolling products and raises the sum to the power of 2.
By using the mathematical constants π and scalar multiplication, it incorporates a formula that includes this sum and the sum of the squares of the original series.
Finally, it returns the square root of the result.
Additionally, the code applies the realized_2 function to a DataFrame called df using the groupby operation on the date component of the DataFrame index.
def realized_3(series):
series = np.log(series).diff()
numerator = (gamma(1/2)**3)*np.sum((abs(series)**(4/3)).rolling(window=3).apply(np.prod))
denominator = 8 * (gamma(7/6)**3)*np.sum(series**2)
return np.sqrt(numerator/denominator)
df.groupby(df.index.date).agg(realized_3)
A function called realized_3 takes a series as input and performs the following operations:
It takes the natural logarithm of the input series and then calculates the difference between consecutive elements.
It computes the sum of the absolute values of the resulting series raised to the power of 4/3 within a rolling window of size 3. It then calculates the product of these values.
It computes the numerator using a mathematical function (gamma) and the sum calculated in the previous step.
It calculates the denominator using another mathematical function (gamma), a constant, and the sum of the square of the original series. It returns the square root of the fraction obtained from dividing the numerator by the denominator.
The function then applies this realized_3 function to a DataFrame called df using the groupby operation on the date component of the DataFrame index.
Further ideas to explore
Corsi et al. (2008) research paper suggests that we can optimize our strategy by taking into account residuals from GARCH model. In particular, they demonstrate that the residuals of the commonly used time–series models for realized volatility exhibit non–Gaussian properties and volatility clustering. To accommodate these properties, authors extend models for realized volatility by replacing the Gaussian with the more flexible normal inverse Gaussian (NIG) distribution to allow for fat–tails and skewness.
From this paper we also reference the idea of less well-known time-series model, auto-regressive fractionally integrated moving average (ARFIMA), which they claimed in 2005 was a promising strategy for modeling and predicting volatility.
Additionally, we might include current and lagged variables as proxies for the information arrival process which potentially can add insight on future volatility.
Finally, we can explicitly separate quadratic variation into continuous and jump components in order to increase the robustness.
Conclusion
Realized Volatility python is a metric that helps to measure the time-variability of financial series. It is used to measure the volatility of returns and capture the time-variability of financial series. In this article, we discussed advanced metrics of volatility and measures of integrated quarticity. We implemented the estimators in Pandas, NumPy and SciPy python libraries. We discussed the realized fourth-power variation or realized quarticity, realized quad-power quarticity, and realized tri-power quarticity. We also discussed additional volatility estimators such as realized volatility estimator 1, realized volatility estimator 2, and realized volatility estimator 3. Furthermore, we discussed ideas to explore such as the use of residuals from GARCH model, the use of ARFIMA model, the use of current and lagged variables as proxies for the information arrival process, and the separation of quadratic variation into continuous and jump components.
References and Related posts
- The Volatility of Realized Volatility. Econometric Reviews
- Kaggle time-series realized volatility and realized variance notebook
- Blockchain Data Indexer with TrueBlocks
- Machine Learning with Simple Sklearn Ensemble
- How to illustrate log returns vs simple returns
- A How to EfficientNet Classification
- Cross-sectional data – An easy introduction