Ultimate Guide to Python Proxy Scraping with AIOHTTP: Optimize Proxies

- Authors

- Name
- Pavel Fedotov
- @pfedprog
Data analysis often requires collecting a large amount of data from various sources. However, to prevent getting blocked by web servers due to IP restrictions, it is recommended to use a python proxy scraper to access data anonymously. A proxy server acts as an intermediary between your device and the web server, allowing you to hide your IP and access websites that may be blocked or restricted. In this article, we provide a step-by-step guide on how to implement a python proxy scraper using various libraries such as requests, Selenium, BeautifulSoup, and NumPy. Additionally, we also demonstrate how to utilize proxies with AIOHTTP, an asynchronous HTTP client/server library for Python.
Please note that to optimize your proxy scrapping process, we highly recommend using a reliable and efficient proxy service like Bright Data's proxy network. Sign up now using our referral link and get started with a free trial!
What is a proxy server?
A proxy server is a remote server through which you connect to obfuscate your initial address. Since the proxy hides and overlays your authentic IP address with its IP, the destination server can only see the IP of the proxy. Hence, if you rotate proxies with each request, the endpoint will recognize them as separate ones since they are coming from different IP addresses. Thus, you increase the speed and chance of obtaining data for research.
Where is my proxy?
In this article, we demonstrate how to obtain, verify and implement python proxy scraper for free proxies by using python libraries requests, Selenium, BeautifulSoup and NumPy. In particular, we utilize requests which is a python http library that allows for the usage of proxies and multi-threading.
To install pip packages for our tutorial:
pip install beautifulsoup4 requests numpy selenium lxml
Python proxy scraper with requests
To effectively implement python proxy scraper, we first need to check whether the proxy servers are compatible with the target website. Hence, we create a python scraper that collects the proxy server list from Free Proxy List and saves only those that work with our target.
import requests
from bs4 import BeautifulSoup
import numpy
import concurrent.futures
# Get HTML response
html = requests.get('https://www.free-proxy-list.net/')
# Parse HTML response
content = BeautifulSoup(html.text, 'lxml')
# Extract proxies table
table = content.find('table')
# Extract table rows
rows = table.findAll('tr')
# Create proxies result list
results = []
# Loop over table rows
for row in rows:
# Use only non-empty rows
if len(row.findAll('td')):
# Append rows containing proxies to results list
results.append(row.findAll('td')[0].text +':' + row.findAll('td')[1].text)
# Create proxies final list
final =[]
def test(proxy):
# test each proxy on whether it access api of hh.ru
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0'}
try:
r = requests.get("https://httpbin.org/ip", headers=headers, proxies={'http' : proxy}, timeout=1)
if r.status_code==200:
final.append(proxy)
except:
pass
return proxy
# test multiple proxies concurrently
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(test, results)
# to print the number of proxies
print(final)
print(len(final))
# save the working proxies to a file
numpy.save('file.npy', final)
This python proxy scraper script yielded 295 proxy servers that work with our target website: HeadHunter.
Python proxy scraper with selenium
We also create a python proxy scraper script that additionally uses selenium library to scrape and check the proxy server list from Advanced Name.
from selenium import webdriver
from bs4 import BeautifulSoup
import numpy
import concurrent.futures
import requests
dr = webdriver.Chrome(executable_path="C:\YourPath")
dr.get("https://advanced.name/freeproxy?ddexp4attempt=1&page=1")
content = BeautifulSoup(dr.page_source,"lxml")
table = content.find('tbody')
rows = table.findAll('tr')
results = []
for row in rows:
# Use only non-empty rows
if len(row.findAll('td')):
# Append rows containing proxies to results list
results.append(row.findAll('td')[1].text +':' + row.findAll('td')[2].text)
dr.close()
final =[]
def extract(proxy):
#this was for when we took a list into the function, without conc futures.
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0'}
try:
#change the url to https://httpbin.org/ip that doesnt block anything
params = {
'text': f'NAME:C++',
'area': 113,
'page': 0,
'per_page': 100
}
requests.get('https://api.hh.ru/vacancies', headers=headers, proxies={'http' : proxy}, timeout=1, params=params)
final.append(proxy)
except:
pass
return proxy
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(extract, results)
print(len(final))
numpy.save('file.npy', final)
# Parse HTML response
content = BeautifulSoup(html.text, 'lxml')
# Extract proxies table
table = content.find('table')
# Extract table rows
rows = table.findAll('tr')
# Create proxies result list
results = []
# Loop over table rows
for row in rows:
# Use only non-empty rows
if len(row.findAll('td')):
# Append rows containing proxies to results list
results.append(row.findAll('td')[0].text +':' + row.findAll('td')[1].text)
# Create proxies final list
final =[]
def test(proxy):
#test each proxy on whether it access api of hh.ru
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0'}
try:
params = {
'text': f'NAME:C++',
'area': 113,
'page': 0,
'per_page': 100
}
requests.get('https://api.hh.ru/vacancies', headers=headers, proxies={'http' : proxy}, timeout=1, params=params)
final.append(proxy)
except:
pass
return proxy
#test multiple proxies concurrently
with concurrent.futures.ThreadPoolExecutor() as executor:
executor.map(test, results)
# to print the number of proxies
print(len(final))
#save the working proxies to a file
numpy.save('file.npy', final)
In turn, python proxy scraper determined 99 items in the proxy server list.
Proxies with asynchronous HTTP client/server library
We can also use the proxies in asynchronous HTTP client/server library AIOHTTP for asyncio and Python. Meanwhile Aiohttp-proxy library assists with SOCKS proxy connector for AIOHTTP.
import aiohttp
from aiohttp_proxy import ProxyConnector, ProxyType
import asyncio
import sys
import numpy
if sys.version_info[0] == 3 and sys.version_info[1] >= 8 and sys.platform.startswith('win'):
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
async def fetch(url, proxy):
host, port = proxy.split(':')[0], proxy.split(':')[1]
connector = ProxyConnector(
proxy_type=ProxyType.HTTP,
host=host,
port= int(port),
)
async with aiohttp.ClientSession(connector=connector,trust_env=True) as session:
async with session.get(url) as response:
return await response.text()
if name == "main":
data = numpy.load('file.npy')
loop = asyncio.get_event_loop()
l = loop.run_until_complete(fetch('http://api.hh.ru/', data[-1]))
print(l)
loop.run_until_complete(asyncio.sleep(0.1))
loop.close()
Summary
In this article, we demonstrated how to implement a python proxy scraper. A proxy scraper is a tool that allows you to access and extract data from websites that are not hosted on your own website. This can be useful for a variety of reasons, such as exploring a website that you can't access or for verifying the authenticity of a website. Nevertheless, free proxy servers will quickly get flagged since too many people use them.
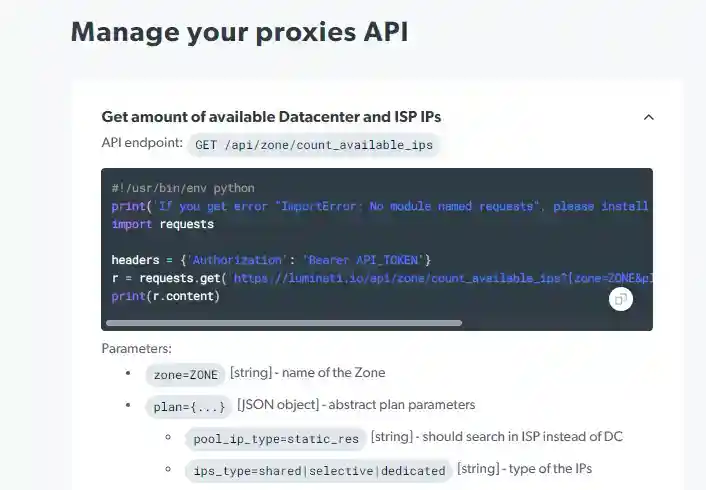
For more reliable service we recommend paid residential proxy servers that Bright Data provides. Formerly known as Luminaty the third-party service has a well-written api documentation for python that you can use to manage your proxies.